

In the last two years, we’ve seen language models explode in scale, performance, and impact. But behind every GPT-style headline lies a quieter, arguably more exciting movement: the rise of small teams building large models with constrained resources. Recently released Nanotron’s UltraScale Playbook showcases one of the best examples of this. Their goal was: train performant LLMs from scratch at the billion-parameter scale and document the entire journey. No secrets. Just lessons.
All thanks to a rockstar team: Nouamane Tazi, Ferdinand Mom, Haojun Zhao, Neuralink, Mohamed Mekkouri, Leandro von Werra and Thomas Wolf.
Below are few notes about what I found fascinating, and what I’m still trying to understand.
Why Scaling LLMs Is More Than a Numbers Game
If you’ve ever wondered whether you need $10M of compute to train an LLM from scratch—the answer, increasingly, is no.
The original GPT-3 had 175B parameters. But since then, we’ve learned (thanks in part to DeepMind’s Chinchilla paper) that size alone doesn’t determine quality. Instead, scaling laws show that data volume and training strategy matter just as much—if not more—than raw parameter count.
Nanotron’s work shows how thoughtful engineering can produce strong, open models in the 1.5B range—cost-efficient, performant, and reproducible.
Peeking Into Nanotron’s Playbook
The UltraScale Playbook is a gold mine of experience. It's essentially an open lab notebook that covers a bunch of aspects:
- Model architecture and tokenizer decisions
- Compute stack
- Dataset selection, cleaning, and curriculum
- Hyperparameters, learning rates, loss curves
- Observations, trade-offs, and open questions
Lessons That Stood Out
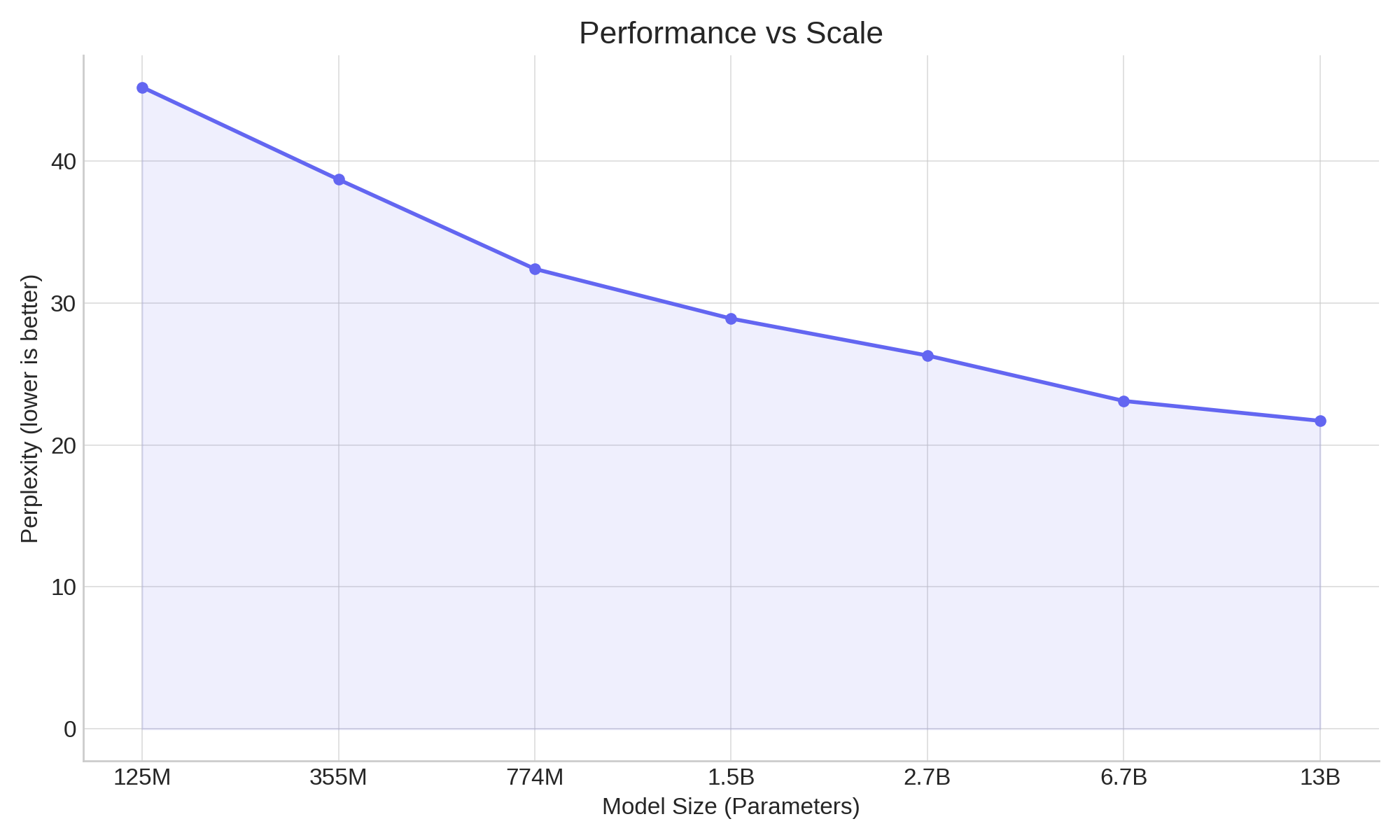
1. Scaling Isn’t Just About Parameters
A billion-parameter model sounds impressive. But if it’s poorly trained, it’s just a large failure.
Nanotron’s experiments reinforce a post-Chinchilla perspective: a smaller model trained well can outperform a larger one trained poorly. The sweet spot is in balance:
- Enough parameters to capture complexity
- Enough data to teach generalization
- Enough compute to train effectively
2. Engineering for Efficiency Is Its Own Discipline
What makes a 1.5B model feasible for a small team? A modern training stack:
- FSDP (Fully Sharded Data Parallelism)
Splits models and gradients across GPUs - ZeRO optimizations
Reduce memory load and redundancy - Mixed precision (bf16/float16)
Faster compute with minimal loss in quality - Efficient I/O and dataloading
To avoid bottlenecks when training on massive corpora
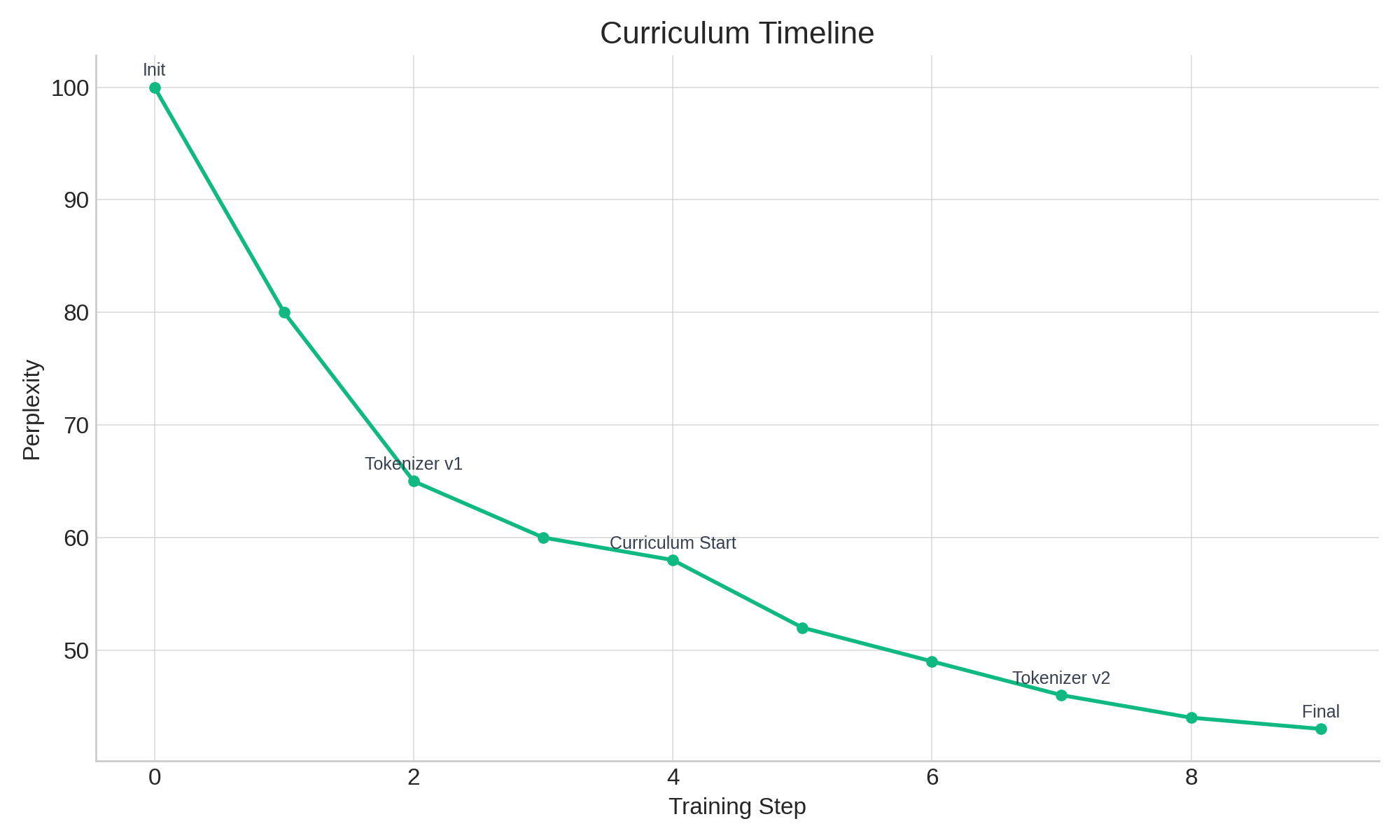
3. Data Quality > Data Quantity
One of the most interesting sections in the playbook is on curriculum learning and tokenization. Rather than simply scaling up data, Nanotron:
- Applied early-stage curriculum: Start training with simpler, cleaner texts
- Iterated tokenizer vocabularies: Byte-level vs word-piece vs adaptive schemes
- Used high-quality corpora (CCNet, RefinedWeb, etc.) rather than raw Common Crawl
Further Questions
- Right unit of “quality” for open LLMs.
- Replicability of these results on other language domains or tasks.
- How to we evaluate the long tail of generalization?
