

Building a high-quality RAG system starts with robust data ingestion and curation. We need to gather the enterprise data that will serve as our LLM’s external knowledge source – this may include documents (PDFs, HTML pages, Word docs), knowledge base articles, wikis, database records, etc. Our goals are to collect, clean, and prepare these data into a central repository that is easy to query. In practice, raw data is often unstructured and noisy, so simply dumping everything into a vector store will yield poor results. Instead, we should establish a pipeline to systematically refine the data before it ever reaches the LLM.
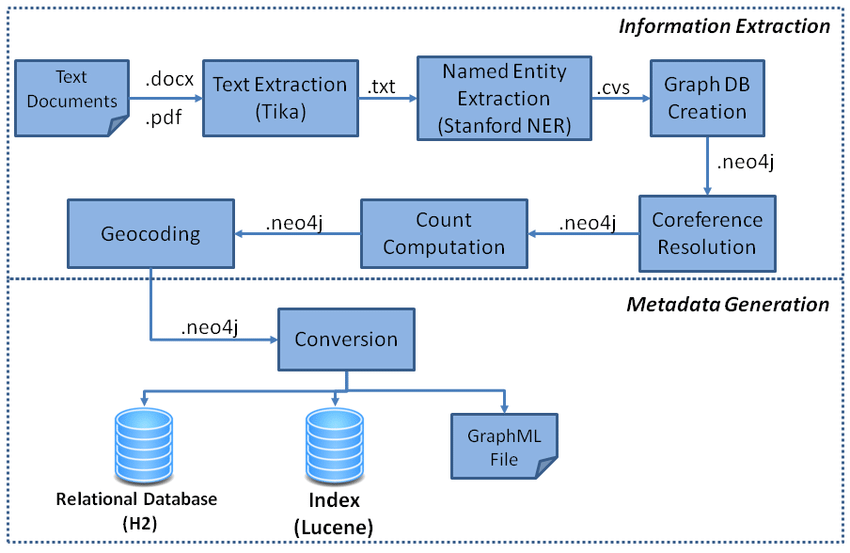
Key tasks in data curation include
- Collecting data from all relevant sources
e.g. crawling internal websites, extracting text from PDFs, exporting database entries. Tools like NVIDIA’s NeMo Data Curator can automate web crawling and text extraction at scale. - Cleaning and preprocessing text
fixing encoding issues, removing boilerplate or irrelevant text, splitting large blobs into logical units. - Deduplication
eliminating exact and fuzzy duplicates so that the knowledge base isn’t weighed down with redundant text. NeMo Data Curator supports document-level deduplication (including fuzzy and semantic matching) to ensure each document is unique.
Organizing and storing the curated data in a reliable, queryable format – here we leverage Delta Lake on Databricks, which provides an ACID-compliant data lakehouse. We might store the data as a Delta table with columns like
document_id, text, and metadata (source, date, etc.). This unified store makes it easy to keep data up-to-date and in sync with downstream indexes.
Quality filtering: removing low-quality or inappropriate content (very short snippets, pages with gibberish or repetitive text, toxic or sensitive content, etc.). This can involve heuristic rules (e.g. drop documents with excessive duplicate phrases or weird punctuation) as well as model-based classifiers to detect toxicity or irrelevant content.
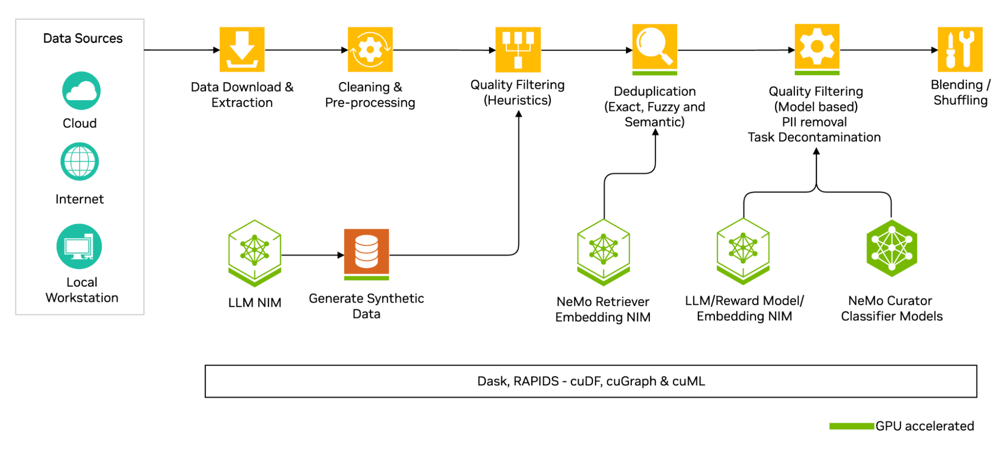
Raw data from various sources (cloud, internal, local) is iteratively cleaned (e.g. Unicode fixes, language separation), filtered (heuristics for length, repetition, etc.), and deduplicated (exact, fuzzy, semantic). NeMo Curator’s distributed tools (MPI, Dask, RAPIDS) enable this pipeline to scale to terabyte-sized corpora.
NVIDIA NeMo Data Curator is a powerful toolkit to automate much of this ingestion process. It provides modules for downloading & extracting text, reformatting and cleaning, quality filtering, and deduplicating at scale. For example, NeMo Curator can fetch web data (Common Crawl or custom URLs), strip HTML to text, normalize Unicode, detect languages, apply regex filters (to remove boilerplate or profanity), and use efficient algorithms to find duplicates. By using a curated dataset, you “ensure that models are trained on unique documents, potentially leading to greatly reduced pretraining costs” – in our RAG context, this translates to a cleaner knowledge base and faster retrieval.
After cleaning, we load the data into Delta Lake. Databricks Delta provides a single source of truth for both structured and unstructured data, with support for versioning and updates. This is crucial because RAG applications often need the latest data. With Delta, we can append new documents or corrections and automatically propagate those changes to the downstream vector index using Databricks’ built-in sync (more on this later). In the past, teams had to stitch together multiple systems for serving data to RAG pipelines, increasing complexity. By consolidating our curated text in Delta Lake, we leverage the Lakehouse’s reliability, security (via Unity Catalog for access control), and scalability benefits right from the start.
Best Practices for Data Ingestion & Curation:
- Start with high-quality sources: The usefulness of RAG is directly tied to the quality of the knowledge base. Prioritize official documentation, reviewed articles, and accurate databases. Use filtering to exclude suspect sources (spam pages, overly noisy logs, etc.).
- Automate pipeline with notebooks or workflows: On Databricks, you can create a scheduled job (notebook) that runs the ingestion pipeline – e.g., daily crawl new content, apply NeMo Curator filters, and upsert to the Delta table. This keeps your RAG system’s knowledge fresh.
- Track data lineage and versions: Use Delta’s versioning to know what data was available at a given time. This helps debug issues (e.g., if the model gave an outdated answer, was the latest data ingested?) and supports rollbacks if needed.
- Leverage distributed compute for scale: If you have a trillion-token scale dataset, use NeMo Curator on a multi-node CPU or GPU cluster (it supports MPI and multi-GPU processing). For moderate data sizes, a single Spark cluster on Databricks can also perform cleaning and deduping using UDFs and libraries (though might be less specialized than NeMo’s tools).
Finally, once the raw texts are curated and stored in Delta, we have a clean knowledge corpus ready to feed into the next stages. The Delta table serves as the bridge between data engineering and model engineering in our RAG system.
