

The final step is deploying the RAG system so that end-users or applications can consume it, and setting up an operational workflow to maintain it. We’ll discuss various deployment architectures and considerations on AWS, using NVIDIA and Databricks components.
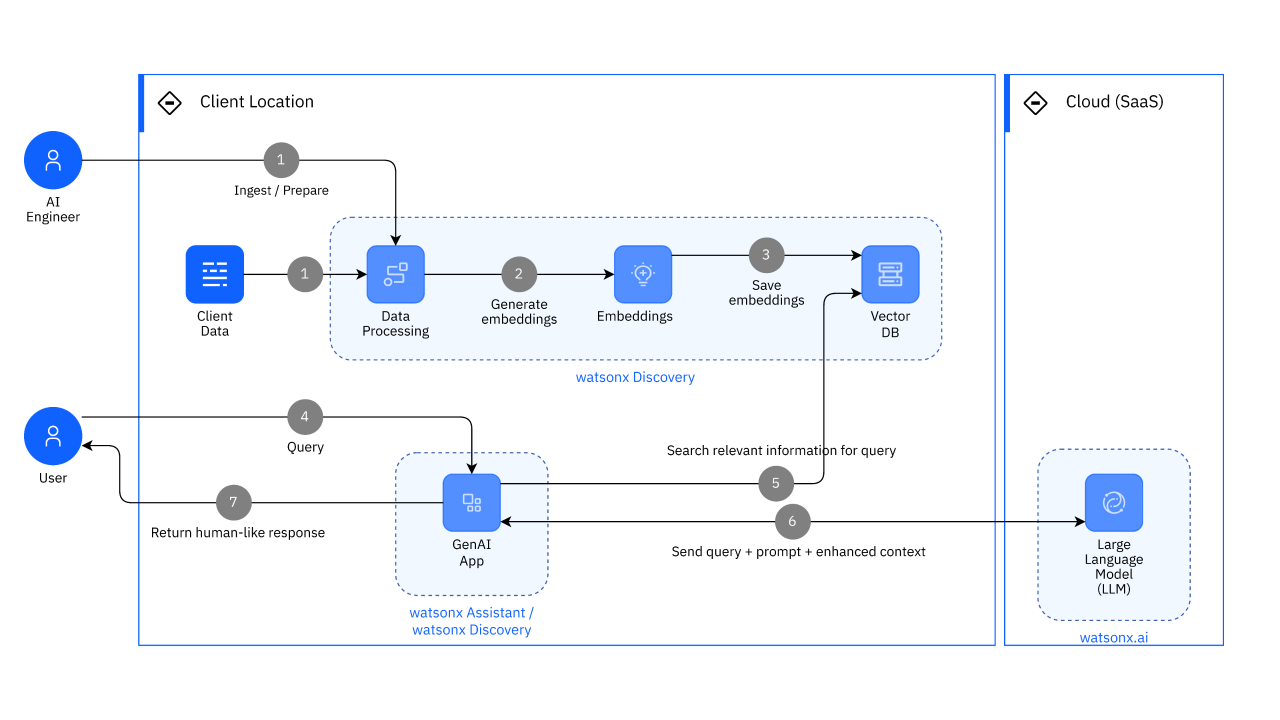
Monolithic vs. Microservice Deployment
One design decision is whether to deploy the RAG pipeline as a single service or as multiple specialized services:
- Monolithic service
You could wrap the entire process (from query to answer) into one service endpoint. For example, a Flask or FastAPI app that, upon receiving a query, internally calls the embedding model, vector search, and LLM, then returns the answer. This is straightforward and ensures all parts live together (no network hops between them). You might do this if you’re deploying on a single powerful machine (e.g., one AWS instance with 4×A100 GPUs might run both the embedding and LLM models concurrently). Databricks Model Serving could also facilitate this: you write a PyFunc that does the retrieval and generation inside, and serve that as one API endpoint on a cluster. - Microservices
Alternatively, you might separate concerns – e.g., one service for the vector database (maybe a Weaviate instance or Databricks SQL endpoint for vector search), and another for the LLM (like a Triton server hosting the model), and an orchestrator that calls them in sequence. This adds complexity (you need to handle routing and errors between services) but offers flexibility and independent scaling. For instance, if embedding or vector search become bottlenecks, you could scale those out separately. Many production systems have, say, a separate ElasticSearch or Weaviate cluster, and they just call that from their application backend.
Using NVIDIA Triton on AWS
If you opt to host models via Triton, you could package your quantized TensorRT engine (or just the model if Triton will auto-optimize it) in a Docker container. AWS offers several ways to deploy containers:
- AWS SageMaker endpoints
SageMaker can deploy a custom container to an endpoint, managing autoscaling and inference. This is suitable if you want a fully managed experience for the model. NVIDIA has published Triton integration with SageMaker in some cases. - AWS ECS/EKS
You can use Elastic Container Service or Kubernetes (EKS) to run the Triton container. This is more DIY but gives you control. For example, you might run a dedicated EC2 instance with Triton for the LLM, and maybe another for an embedding service. - Databricks
You might not need Triton if you are using Databricks model serving; however, you could still use Triton for maximum performance and call it from a Databricks notebook or job when needed.
Databricks Model Serving
As of 2025, Databricks has the ability to serve models (including LLMs) on endpoints that are accessible via REST. If your whole pipeline is implemented in a notebook, you can also use a Databricks Jobs API to trigger it. But for interactive latency, the Model Serving is more appropriate. One caveat: ensure the endpoint has GPUs attached if serving an LLM that requires GPU. Databricks was working on GPU serving capabilities – likely you can attach an instance type like g5.xlarge to a serving endpoint now. Model Serving integrates with MLflow, meaning you can easily roll out new model versions, A/B test, etc.
AWS SageMaker for a full pipeline
Another approach is to build the pipeline as a SageMaker Inference Pipeline – a sequence of containers: one for embedding & retrieval, feeding into one for generation. SageMaker can host multi-container models where the output of one container is passed to the next. This could elegantly separate the concerns (first container does query -> vector search -> prepares prompt, second does LLM). However, configuring this pipeline might be non-trivial, and you might lose some flexibility.
Inference Cost and Autoscaling
Deploying an LLM on GPU 24/7 can be expensive. You might implement autoscaling policies – e.g., run on demand during business hours, or scale down to 0 at night if it’s an internal tool. Both Databricks and SageMaker have options for scaling. Also, you might consider using AWS Lambda + GPU (through container images) for spiky loads, but cold start on GPU Lambdas can be an issue and not all large models fit in Lambda’s limits.
CI/CD for RAG
It’s important to treat the pipeline components as you would any software:
- Use Infrastructure-as-Code (Terraform, CloudFormation) to define your deployment resources (clusters, endpoints).
- Use MLflow Model Registry or a similar mechanism to version your models (e.g., a new embedding model or a quantized LLM). Promote models to production after testing.
- Automate testing of the pipeline on sample queries whenever you update any component (embedding model version, new data ingestion code, etc.) to ensure nothing broke.
Maintaining the Knowledge Base
Set up a process to regularly update the data in the vector index. If you add a new document to the Delta table, the Databricks Vector Search will auto-index it (thanks to Delta sync). If using a custom solution, consider running a daily job to embed any new documents and add them to your vector store. Also, plan how to remove outdated information – you might either delete old vectors or mark them with a flag so they can be filtered out. This is part of ops: ensuring the system’s knowledge stays current and relevant.
Monitoring and Logging
We touched on monitoring outputs, but also monitor system health:
- Track the number of queries, latency percentiles, GPU utilization, memory usage, etc. Tools like Prometheus + Grafana can be employed, or cloud-specific monitoring (CloudWatch for AWS, or Databricks native monitoring). This helps to see when you might need to scale up or if any component is a bottleneck.
- Log errors carefully. If the LLM service fails to respond or times out, the user should get a graceful message. Implement retries for vector DB queries if needed. For debugging, it’s useful to log the retrieved documents for each query and the final answer somewhere (even if just in a secure log) so that you can audit how the model arrived at an answer.
Security considerations
In an enterprise, ensure proper authentication and encryption:
- If exposing an API, use HTTPS and require an auth token or integrate with your identity provider.
- Ensure that only authorized systems or users can query the RAG system, especially if it can access sensitive data.
- Mask or redact any sensitive info in logs. For example, if users might query about personal data, you don’t want full queries with names to be sitting unencrypted in log files.
User Experience and Feedback
If this RAG system is user-facing (like an internal assistant), consider providing a feedback mechanism. A simple thumbs-up/down on answers can feed back into evaluation metrics or even a fine-tuning dataset later (as a form of reinforcement learning signal). Databricks notebooks or apps could capture that, or if integrated in a chat UI, store the feedback in a database.
Finally, keep an eye on model improvements and data drift. The field of LLMs is evolving quickly; new models or updates might give you better performance or allow you to reduce cost (e.g., smaller model with same accuracy). Similarly, as your company’s data grows, the retrieval strategy might need to be adjusted (maybe splitting indexes by domain, etc.). Plan for periodic reviews of the system (maybe every quarter) to incorporate the latest best practices.
Deploying a RAG system is certainly a complex endeavor, but with the combination of NVIDIA’s optimized AI software and Databricks’ unified platform on AWS, much of the heavy lifting is handled for you.
