

Traditional IT strategy prized economies of scale – building big, standardized systems to maximize efficiency and ROI over long periods. Today, leading companies instead chase economies of speed – the ability to learn, adapt, and deliver value faster than competitors. This shift has profound implications for enterprise architecture. No longer merely a back-office cost center, IT is seen as a strategic differentiator and competitive advantage. This post explores how enterprise architecture must evolve to enable speed over scale.
From IT Cost Center to Digital Competitive Advantage
Businesses that undergo digitalization in their majority still see IT as a support function – a necessary cost center focused on efficiency and stability. Success is measured in cost savings and reliable uptime, not market impact. That mindset has been upended in the last 10–15 years as software “eats the world” and digital-native competitors disrupt incumbents. Modern enterprises realize that technology is core to business strategy, not just overhead.
IT must shift from being a cost center to a source of competitive advantage. This requires fundamentally changing how IT operates and is perceived within the organization.
In practical terms, IT is now expected to drive innovation, enable new business models, and directly contribute to revenue growth.
Leading organizations have explicitly embraced this shift. For example, Capital One’s CEO famously said banks must “think more like technology companies and maybe a little less like banks,” underscoring the strategic value of tech in finance.
At Capital One, a decade-long modernization (including moving aggressively to the cloud) was aimed at agility and innovation – with efficiency as a welcome side effect. “Efficiency was never the objective function… it was one of the many benefits of a tech transformation,” CEO Richard Fairbank explained. In other words, the goal was to increase capability and speed, enabling the business to compete in real time, personalize services, and rapidly develop new offerings. Treating IT as a competitive weapon changes the investment calculus: projects are justified not only by cost savings but by the opportunity cost of not moving quickly enough.
This new mindset also elevates the role of enterprise architects and IT leaders. They are no longer just custodians of standards and cost efficiency; they must become change agents who help the enterprise respond faster to change.
By moving up and down levels, architects ensure technology decisions drive business outcomes and that business needs inform technical priorities. In the context of economies of speed, this means architects focus on time-to-value: enabling shorter feedback loops, quicker experiments, and more frequent deliveries of value to customers. The following sections delve into what economies of speed vs. scale means, and how enterprise architecture practices are adapting to prioritize fast flow and flexibility over static scale and efficiency.
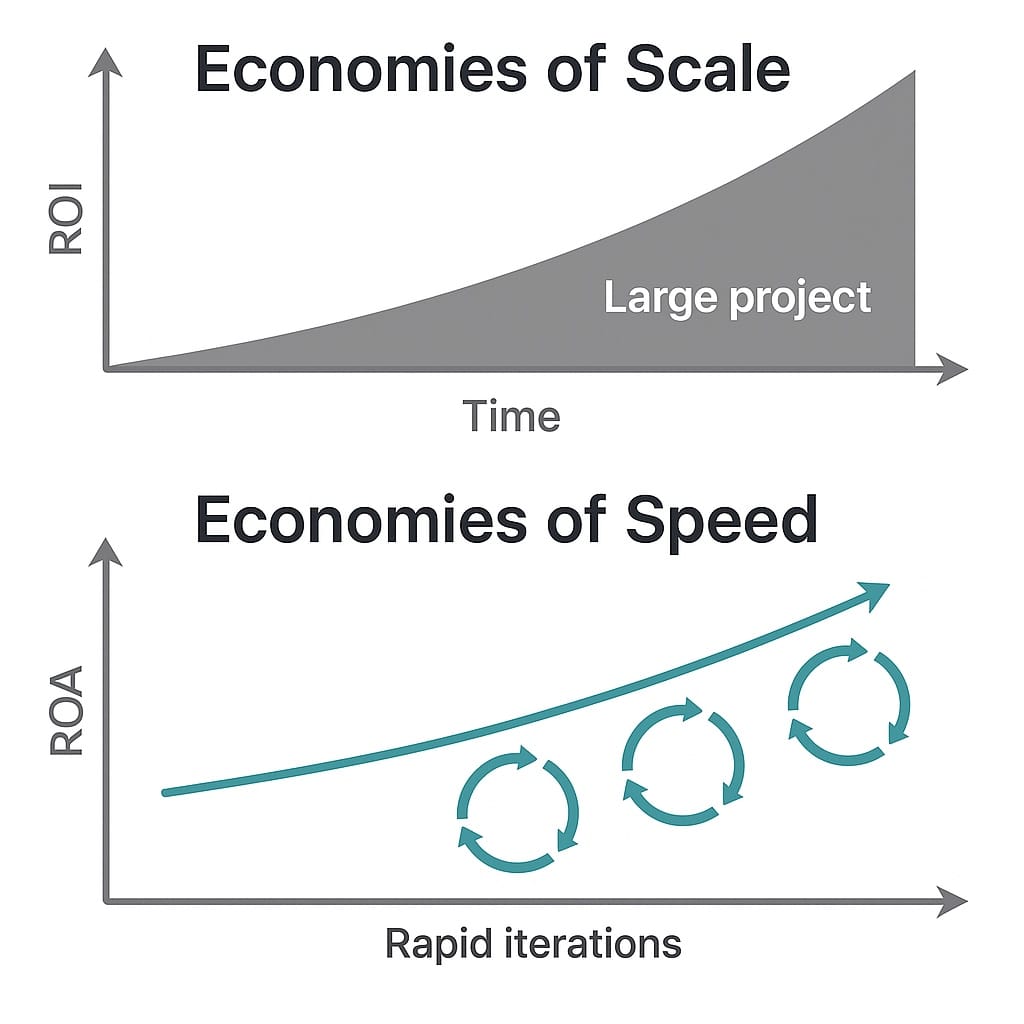
Economies of Scale vs. Economies of Speed
Traditional IT and industrial-era enterprises optimized for economies of scale. In an economy of scale, you invest heavily in building something once – say a large piece of software or infrastructure – and then reap returns by using it as widely and as long as possible. The bigger and more standardized your systems, the lower the unit cost. This approach makes sense when markets and requirements change slowly. If things stay steady, running a big system longer yields better ROI. Key metrics in a scale-oriented mindset include total cost of ownership, utilization rates, and return on investment over years. Plans are made with “absolutes” – fixed budgets, fixed timelines, fixed capacity assumptions. Change is something to minimize or tightly control.
By contrast, economies of speed focus on rate of learning and adaptation. As Gregor Hohpe puts it, economies of speed are “about learning quickly, having constant change, being able to listen, being able to course-correct, being Agile”. Instead of assuming a steady-state world, this approach assumes continuous evolution and uncertainty. The faster an organization can experiment, gather feedback, and respond, the more competitive it can be. In a volatile business environment – shaped by rapidly shifting customer expectations, emerging technologies, and disruptive entrants – speed of iteration beats sheer size. This is essentially economies of scale per unit of time: how much value can you deliver per week or per day, rather than per release or per project.
The vocabulary and measures of success therefore change. In a speed-focused model, you talk in relatives and rates rather than absolutes. Instead of a fixed budget, you manage a burn rate and cost of experimentation – investing in many small bets to see what works. Instead of total capacity, you track velocity of delivery (e.g. deployments per day, features per quarter) and how quickly you can scale a successful idea up or pivot when needed. It's crucial to think in terms of “return on agility”:
What is my return on having the ability to react quickly if something changes?
A fast reaction to a market opportunity or risk could be worth far more than incremental savings from a bulk purchasing deal or a fully utilized server farm. Cloud computing aligns well with this mentality – it “matches the mental model of economies of speed” by providing on-demand resources at granular cost, letting teams ramp experiments up or down quickly.
Crucially, optimizing for speed often requires breaking some old rules. Practices that maximize efficiency at scale – centralization, heavy reuse, strict standardization – can impede speed by adding friction or coordination cost. For example, in a scale world, reusing components and avoiding duplication is a virtue to reduce cost.
But in a speed-oriented world, obsessive reuse can become a bottleneck: teams spend months aligning on a shared component when they could have delivered two separate solutions in parallel. Some digital companies have even begun to explicitly favor duplication because their business environment rewards economies of speed.
Evolving a widely reused shared service means coordinating with many stakeholders, which “can slow down innovation”, so sometimes it’s faster to tolerate a bit of duplication and move quickly. Amazon famously allowed different teams to build similar capabilities if it helped them innovate faster – a stark departure from traditional IT governance. Of course, duplication has a cost, but in a fast-moving market, slowness costs more.
Btw, on top of that, Bezos opted-in for a further radical approach. He modularized all internal services teams early on - which soon resulted in a success with AWS.

None of this is to say that scale is irrelevant – cost efficiency and scalability still matter, especially for core platforms. The key is recognizing where each model applies.
The economy of scale is about doing more of the same thing cheaper; the economy of speed is about doing new things sooner.
Much of IT is optimized for economies of scale, which largely have been replaced by economies of speed. That transition is a difficult one. Shifting from a scale mindset to a speed mindset can feel like turning a container ship. It pressures the culture, processes, and architecture of IT. In the next section, we’ll look at how enterprise architecture must change to support this new goal of speed.
Evolving Enterprise Architecture for Speed
Enterprise architecture (EA) in a scale-centric world often meant centralized planning, rigid standards, and top-down governance to eliminate redundancy and control costs.
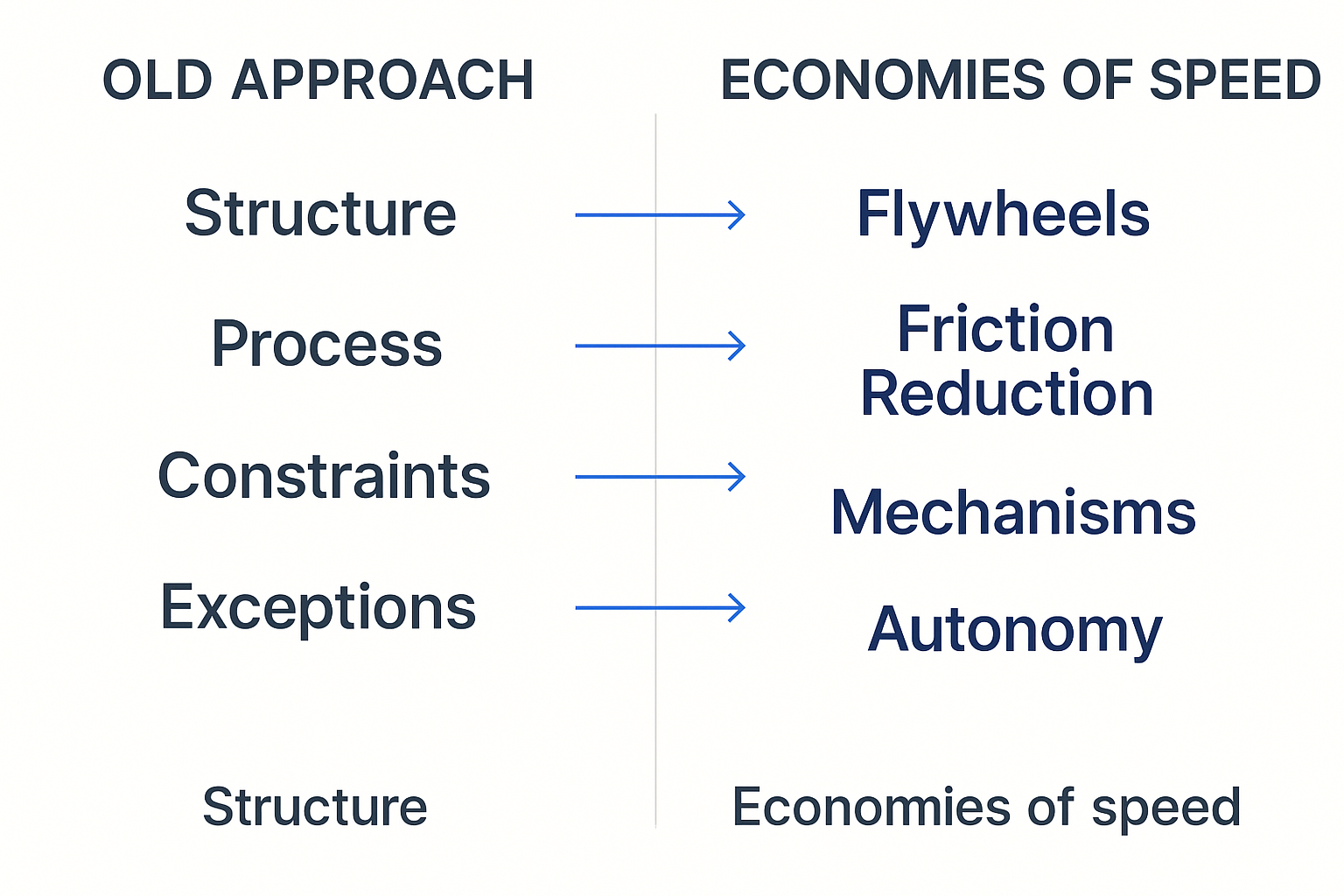
In a speed-centric world, EA’s role is flipped on its head: instead of controlling every detail, architects enable decentralization, autonomy, and fast experimentation – while still guiding the organization within sensible guardrails. It's about moving away from defining rigid structures and processes, and toward creating flywheels, frictionless platforms, automated mechanisms, and autonomy.
In practical terms
- From Structure to Flywheels
Rather than dictating a fixed target architecture (“to-be state”) years in advance, architects focus on creating flywheels – self-reinforcing loops that continuously improve speed and quality. For example, implementing a continuous integration/continuous delivery (CI/CD) pipeline is a flywheel: automated tests and deployments mean code can flow to production faster and more reliably, which encourages more frequent releases, which in turn yields more feedback and improvements. Each turn of the crank makes the next turn easier. EA’s job is to seed these virtuous cycles (such as automated testing, monitoring & feedback loops, and A/B experimentation frameworks) that let teams continuously improve without constant oversight. The focus shifts from drawing static diagrams to optimizing feedback loops across the enterprise. - From Process to Friction Reduction
Traditional EA might enforce detailed processes (change management, approvals, handoffs) to ensure consistency. In a speed paradigm, those processes often become friction. The architect’s mission becomes removing impediments to fast flow. This means investing in developer experience and internal platforms, streamlining governance, and automating every step possible.
If teams must navigate bureaucratic paths or special favors to get servers, environments, or approvals, your IT processes are introducing artificial wait times and inconsistency. Leading firms eliminate these delays by providing self-service cloud infrastructure, on-demand environments, and one-click deployments – giving every team equal and immediate access to the resources they need.
Enterprise architects should identify where slow handoffs or review boards are hurting time-to-market, and replace them with automated guardrails and self-service mechanisms. Security and compliance checks, for instance, can be built into pipelines so that they run continuously rather than requiring a meeting. The goal is to “reduce friction” so that teams can move faster with confidence. - From Constraints to Mechanisms
In scale mode, architecture often imposes many constraints – approved tech stacks, strict data models, single sources of truth – to minimize variance. While some constraints remain important, speed mode favors lightweight mechanisms over rigid rules.
Mechanisms are automated or procedural enablers that guide desired behavior without requiring case-by-case intervention. Amazon is famous for this approach. Instead of a central committee approving every API design, they instituted an API gateway and standards that teams follow, and tools that lint or flag issues. Instead of code reuse mandates, they built an internal service registry and tooling that makes discovering and integrating existing services easy. These might include templates, frameworks, paved-road libraries, and platform services that bake in best practices (logging, authentication, compliance) so teams don’t have to reinvent or seek approval for each basic capability. By embedding policies in code and automation, EA ensures consistency without slowing teams down. A developer platform that offers ready-to-use pipelines, standardized infrastructure-as-code modules, and validated architecture blueprints is an example of a mechanism enabling speed with governance. Deploying such mechanisms lets you stay on track even as you decentralize decision-making. - From Exception Approval to Autonomy
In traditional governance, teams often must request exceptions to standards or additional capacity – a process that can be slow and stifle innovation. In a speed-focused organization, autonomy is a feature, not a bug. Enterprise architecture must foster autonomy by pushing decision-making to the edges (to the teams closest to the problem) and trusting them to act within broad guardrails. This is supported by the above points: if you provide good flywheels, low-friction platforms, and automated guardrails, you can let teams decide locally without constant oversight.
The architect’s role shifts to coaching and context-sharing rather than command-and-control. Autonomy doesn’t mean chaos: it means teams have clear ownership of their products and the freedom to execute rapidly, aligned by a strong tech strategy and platform. Many companies adopt “you build it, you run it” DevOps culture to support this, giving teams end-to-end responsibility. The payoff is that decisions don’t wait on a distant committee; teams can pivot and innovate as fast as the market demands, which is the essence of economies of speed.
Actionable Frameworks for Speed Enablement
Embracing economies of speed in enterprise IT requires not just mindset shifts, but concrete changes to organizational structures and operating models. Several modern frameworks and models have emerged to help enterprise architects and IT leaders implement speed at scale.
Below, we explore a few key ones – platform thinking, team topologies, and product-centric operating models – and how they contribute to agility without descending into chaos. We’ll also highlight real examples where these approaches paid off.
Platform Thinking: Building for Speed and Scale
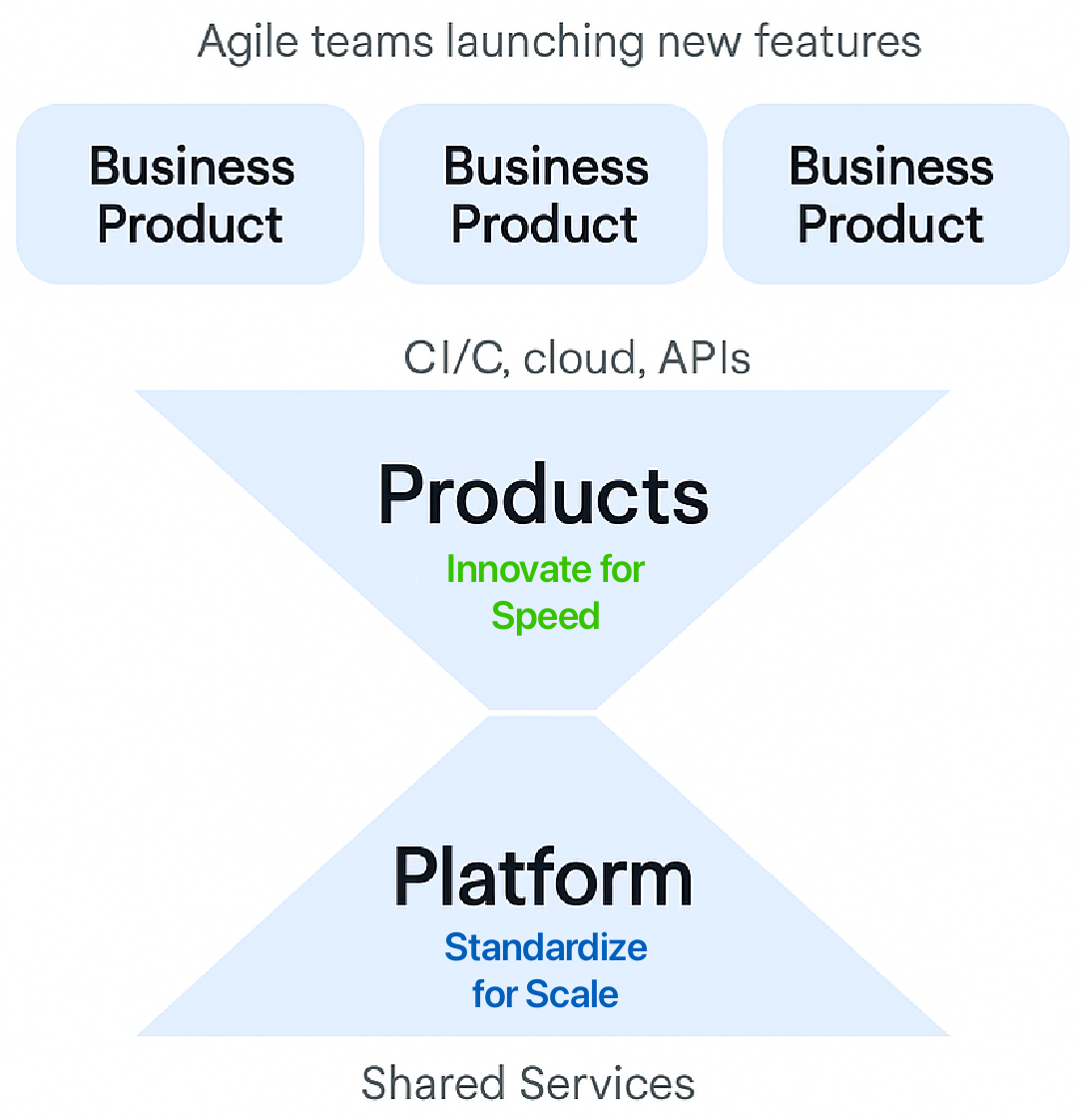
One powerful way to reconcile speed with the needs of a large enterprise is platform thinking. The basic idea is to create internal platforms – a set of shared services, APIs, and tools – that standardize the fundamentals (so you get economies of scale in those layers) while enabling fast innovation on top (economies of speed at the business layer).
In traditional IT, we often picture a single pyramid: a broad base of common infrastructure and a narrow top of business-specific apps. A double pyramid separates concerns: the bottom pyramid provides a stable, standardized platform (common services, infrastructure, data management) yielding economies of scale, while the top pyramid (upright) consists of diverse, rapidly evolving products built by business-line teams, yielding economies of speed. The point where they meet is a well-defined platform interface: essentially a product line offered internally.
Real-world examples of this abound. Amazon is a poster child: it transformed its IT by breaking the monolithic architecture into hundreds of microservices (an internal platform of building blocks) and mandating that every service be exposed via clean APIs. This enabled autonomous two-pizza teams to rapidly develop new features and even new businesses (like AWS itself) on top of common components. Amazon’s platform approach achieved the extraordinary customer-serving capabilities enabled by size with the speed and nimbleness of a startup.
By decoupling systems, Amazon eliminated bottlenecks – teams could deploy independently at will. In fact, after adopting microservices and an API-driven platform, Amazon went from deploying new code once every few months to deploying every 11.7 seconds on average (as reported in the “Amazon Unboxed” case) – a testament to extreme economies of speed at scale. The trade-off was accepting some duplication and inconsistency, but Amazon manages that with lightweight governance and an emphasis on mechanisms over rules. As one AWS report notes, small empowered teams incur a risk of duplication and siloed development.
The solution is not to recentralize, but to have the right governance structure in place to decide when and how to combine efforts that are purely replicative, while not stifling teams’ abilities to drive innovation. In practice, this means periodically refactoring or consolidating systems that have organically diverged when the time is right, but not preemptively shutting down experiments in the name of uniformity. A well-run platform organization knows when to let teams run and when to pull back for synergy.
Key to platform thinking is treating internal platforms “as products, not projects.” Platform teams should market their services to internal developers, iterate on feedback, and measure success by adoption and developer productivity, not just technical KPIs. Manuel Pais and Matthew Skelton (authors of Team Topologies) emphasize that a platform’s purpose is to reduce cognitive load for product teams – i.e. handle the undifferentiated heavy lifting – rather than to impose centralized control. As Martin Fowler notes, a good platform provides self-service, easy-to-consume capabilities so that stream-aligned teams can concentrate on supporting the business needs, not on (for example) data storage issues.
This requires a mindset shift for platform engineering: developer experience (DX) is paramount. For example, at Netflix, the Engineering Tools team built paved-road solutions (like Spinnaker for continuous delivery) that most developers happily adopt because they make work easier and faster. This is platform-as-product thinking in action – the platform succeeds when it makes other teams succeed.
Critically, platform thinking strikes a balance between standardization and innovation. By standardizing the infrastructure, pipelines, and cross-cutting capabilities (security, logging, etc.), you get reliability and efficiency (scale benefits). By allowing variability and freedom in the product layer (where teams build unique customer-facing features), you get creativity and agility (speed benefits). A well-designed platform gives you controlled speed – developers move fast along “golden paths” that offer both velocity and guardrails. Enterprise architects should champion this approach: invest in internal platforms (or leverage cloud platforms) that provide a reliable foundation and let business teams focus on rapid innovation. A useful mental model is to ask, “Could a new team deliver a new idea in days by assembling services on our platform?” If not, figure out what’s missing or slow (e.g. environment provisioning, data access, compliance checks) and fix that at the platform level. Over time, the organization builds an innovation engine that speeds up as it grows, rather than slowing down.
Team Topologies and Organizational Structure for Speed
Organizational design is just as crucial as technical architecture in achieving economies of speed. Team Topologies, a framework by Skelton and Pais, provides a blueprint for structuring IT teams to maximize flow and minimize handoffs. The core idea is to organize around products or value streams (what the framework calls stream-aligned teams), and to support them with specialized platform teams, enabling teams, and (where necessary) complicated-subsystem teams. This model explicitly moves away from traditional silos (by function like database, frontend, ops) and toward long-lived, cross-functional teams centered on business capabilities. Such teams can deliver end-to-end value without waiting on other teams, which is a huge boost to speed.
A stream-aligned team is essentially a product team – “responsible for software for a single business capability,” and thinking of their work as an ongoing product, not a project. For example, instead of a “CRM project team” that disbands after delivery, you have a Customer Platform Team that continuously improves the customer relationship management system as a product, iterating based on user feedback. These teams are full-stack and full-lifecycle: they have the skills to develop, test, deploy, and operate their software within the team. This aligns responsibility with control, enabling faster decision-making. Importantly, stream-aligned teams are meant to be small and nimble – often referenced as the “Two Pizza Team” rule (5–10 people) popularized by Amazon. Smaller teams have less overhead and can communicate more easily, which again improves speed. A team of 6 can usually move faster than a team of 60 (and with modern cloud and devops tools, a team of 6 can accomplish what used to require 60 in terms of infrastructure).
However, a key insight of Team Topologies is that small product teams can become overwhelmed if they have to handle everything themselves (especially in a large enterprise setting with complex legacy systems). If every team has to be an expert in networking, databases, compliance, UX, etc., they’ll slow down. Enter the Platform and Enabling teams: these are supporting cast that ensure the stream-aligned teams can stay focused. A platform team in this context is a bit like what we described in Platform Thinking – they provide internal services and tools that the product teams consume in a self-service way.
For instance, a platform team might provide a CI/CD as a Service, or a database provisioning API, or a shared machine learning feature store – anything that multiple teams need. By using the platform, stream teams avoid duplicating work and can deliver faster. Team Topologies emphasizes that platform teams must act as service providers and treat other teams as customers. They should have a product mindset, continuously improving the platform based on feedback and usage patterns. This again fosters speed: when the platform team smooths out a common problem (say, authentication or logging), all product teams benefit and no longer lose time on it.
Enabling teams are another construct – they are like internal consultants or educators that help product teams adopt new skills or technologies. For example, if you’re introducing Kubernetes or event-driven architecture, an enabling team might consist of experts who pair with multiple stream-aligned teams for a while, upskilling them and removing impediments. Enabling teams are temporary and collaborative; their goal is to disseminate knowledge and best practices quickly across the org, and then dissolve or move to the next challenge. This prevents each team from struggling in isolation or reinventing the wheel – a fast way to spread capability without formal hierarchy. By having these auxiliary team types, an enterprise can innovate quickly (each stream team runs ahead on its product) while not fragmenting (because platform and enabling teams keep the whole system coherent and efficient).
A concrete example
ING Bank’s agile transformation in 2015 mirrored many of these principles. The bank reorganized into ~350 nine-person squads (cross-functional teams) organized into tribes, very much like stream-aligned teams focused on specific customer journeys or products. They drew inspiration from tech firms like Spotify. They improved time-to-market, higher employee engagement, and increased productivity. ING found that agility is about flexibility and the ability of an organization to rapidly adapt and steer itself in a new direction… minimizing handovers and bureaucracy, and empowering people.
This is essentially the philosophy of team topologies:
- Reduce handovers by forming autonomous teams
- Cut bureaucracy by enabling those teams with platforms and lean governance
- Empower people (give teams ownership)
With these changes, ING was able to deliver features faster (in some cases going from monthly releases to multiple releases per day in certain areas) and respond to customer needs in real-time. They also report higher engagement – when teams own their work, morale improves, which further boosts productivity in a virtuous cycle.
Amazon’s two-pizza teams
This approach is effectively a precursor to this model. Amazon organized small autonomous teams each owning a microservice or product. They coupled this with an internal platform (AWS-like infrastructure) and a culture of enabling experiments. As Amazon grew, this structure was crucial to avoiding the slowdown common in large enterprises. Amazon Web Services’ own team notes that to truly become a high-performing agile organization, you must look at your organization structure differently… speed of innovation at Amazon relied on an organizational structure of empowered builders.
Small teams close to the customer could make quick decisions without distracting dependencies and competing priorities. This allowed Amazon to continue innovating at a startup pace even as it scaled to tens of thousands of employees. The lesson is clear: structure your teams for streamlined communication and minimal waiting, and you’ll unleash speed. Conversely, if your org chart forces every change through a gauntlet of siloed departments (analysis, dev, QA, ops, security all handled by separate groups), you will never achieve high tempo – the coordination cost and sequential delays will kill agility. Modern enterprise architecture thus extends beyond diagrams of systems – it includes organizational architecture, applying approaches like Team Topologies to ensure the people system is optimized for fast flow.
Product-Centric Operating Model
In tandem with team restructuring, many enterprises are shifting from a project-centric to a product-centric operating model to drive continuous value delivery. In a project-centric model, IT work is organized as discrete projects with start and end dates, specific scopes, and often one-off funding. Teams assemble for the project and then disband or move on when it’s “done.” This model often leads to throwaway outcomes and slow progress: after delivery, there may be little ongoing improvement, and knowledge dissipates as teams scatter. In contrast, a product-centric model treats each software application or capability as a product with a product manager, a dedicated team, and an indefinite lifecycle of iterative enhancement. Funding is allocated to products (or product lines) rather than projects, encouraging teams to continuously improve their product, respond to user feedback, and deliver new increments over time.
The differences between these models are stark:
- In a project-centric setup, IT is seen as a cost center, budgets are approved project by project, and release cycles might be 6–12 months or more. Teams are temporary, and once the project is delivered (often after a long cycle), the team moves on. There’s limited feedback from end-users during development, and success is measured against upfront specs and budgets. It’s a bit like commissioning a building – plan, build, deliver, then hand over.
- In a product-centric setup, IT can become a profit center or value center – since each product is directly tied to business outcomes. Funding becomes more flexible and persistent (a product has an annual budget or investment that can be adjusted as it evolves). Release cycles shrink to weeks or even days, with frequent deployments. Teams stick with “their” product for the long haul, gaining deep expertise and accountability for outcomes. Prioritization is continuous and driven by real user feedback and analytics, not a one-time requirements document. In short, product-centric IT is much more agile and responsive to change. It aligns IT work with business value streams and encourages a long-term view on quality and customer satisfaction.
Enterprise architects can facilitate this shift in several ways. One is by helping define the product taxonomy – essentially mapping the business capabilities to digital products. For example, an insurer might define products like “Quote and Policy Management System,” “Claims Platform,” “Agent Mobile App,” etc., each aligned to a business capability and customer journey. Each product gets a dedicated cross-functional team (as per Team Topologies above) and a product owner who defines the roadmap in business terms. Architects ensure that the dependencies between products are minimized (through APIs, events, and clear domain boundaries) so that each product team can evolve their slice independently at speed. This often involves applying domain-driven design (DDD) to split up a monolithic landscape into bounded contexts that map to product teams – a technical approach that dovetails with the product-operating model.
Another role of enterprise architecture is to establish governance that fits a product model. Traditional PMOs and architecture review boards may need to evolve or dissolve. Instead of gating every project, governance in a product model happens via periodic product reviews, OKRs (Objectives and Key Results), and automated policy checks. Architects might, for instance, set non-functional requirements (security, scalability standards) that all products should meet, but let the teams decide how to meet them – checking compliance via automated scans or pipelines. Metrics like lead time, deployment frequency, mean time to restore (from DevOps Research’s DORA metrics) become important for all product teams, and architects can help implement tooling to measure these and make them visible. These metrics directly indicate speed and stability – e.g., elite performers can deploy on demand and recover from failures within hours. By focusing on such outcomes, architects move the conversation from “did you follow the process” to “are we delivering value quickly and safely?”.
Case in point
Many large organizations have made this shift. Microsoft, for example, moved to a cloud-first, product-centric approach in its Azure DevOps division – abandoning 3-year major releases in favor of biweekly sprints delivering continuous updates to Azure DevOps Services. This not only improved customer satisfaction but allowed Microsoft to keep up with fast-moving competitors. ING explicitly framed its agile transformation as moving to a “One Way of Working” product model – they created product areas and gave them end-to-end responsibility, cutting out layers of middle management. Capital One similarly reorganized IT around products and built a culture of internal open source, where teams contribute to each other’s codebases as needed rather than waiting on formal projects. The result was faster cycles – Capital One went from quarterly releases for mobile app updates to multiple deployments per day, using feature flags to release safely. As another example, Lloyds Banking Group in the UK reported slicing a large monolithic core banking program into smaller product teams, which reduced their delivery times dramatically and allowed incremental delivery of features rather than one big bang after 2 years.
The product-centric model also forces business and IT alignment in a positive way. When you fund a product team continuously, business stakeholders (like a line-of-business head) become more involved in prioritizing that product’s backlog in an ongoing collaboration, rather than throwing requirements over the wall and disappearing until go-live. This collaboration ensures the product is always solving the most pressing problems, which increases the impact and avoids waste. It essentially turns IT into an internal product developer for the business, with shared goals. Over time, this can change the culture: IT staff start caring about customer experience and revenue (not just technical deliverables), and business leaders start embracing agile principles (since they see incremental progress every sprint). This cultural blending is exactly what digital transformation seeks to achieve.
Moving to a product-centric operating model is a cornerstone of achieving economies of speed. It creates a structure where improvement is continuous and responsibility is clear, enabling rapid response to change. Enterprise architects and transformation leaders should guide their organizations through this shift by redefining funding models, realigning teams to capabilities, and updating governance to empower product teams. It’s a non-trivial change – essentially rewriting the “operating system” of IT – but the payoff is huge: faster innovation, higher quality (since teams own what they build), and a more competitive business. This shift can unlock IT’s value, turning it into a true engine of growth rather than a tax on the business.
Real-World Transformation Lessons: Speed in Action
Amazon’s “Invention Machine”
We’ve already touched on Amazon, but it bears repeating as a success story. In the early 2000s, Amazon’s IT was hitting the limits of a scale-oriented architecture; the tightly coupled systems and growing workforce were slowing down innovation. Jeff Bezos and his leadership recognized that to keep their “Day 1” startup mentality, they had to overhaul both technology and team structure. The switch to microservices and two-pizza autonomous teams paid enormous dividends. With independent services, teams could deploy software thousands of times a day across the company.
Amazon also instituted cultural mechanisms like the “API mandate” (every team must expose data via APIs) and “you build it, you run it,” forcing operational accountability to reside with dev teams – which in turn drove teams to build more reliable, automate-able systems. The competitive advantage this conferred is hard to overstate: Amazon can spin up new products (AWS, Prime Video, Alexa, etc.) faster than competitors can react. If a new customer demand or idea arises, an empowered team can often prototype and launch it in weeks.
Many observers have noted that Amazon’s ability to innovate at high speed is a key reason it outpaced brick-and-mortar rivals and even tech peers. By achieving economies of speed at scale, Amazon turned IT into a growth engine. The takeaway for enterprise architects: enabling independently evolvable services and teams is pivotal. Amazon accepted trade-offs (e.g. some duplication, the need for strong DevOps skills in each team) in exchange for agility, and that has proven a winning formula.
ING’s Agile Revolution
ING, a 175-year-old bank, might seem an unlikely poster child for tech agility. Yet, around 2015, ING Netherlands underwent a bold agile transformation precisely to boost speed and responsiveness. They flattened their hierarchy, removed traditional departments, and rebuilt the organization into squads (product teams) and tribes, heavily inspired by the Spotify model. Peter Jacobs, ING’s CIO, explained that there was “no burning platform” (ING was profitable and not in crisis) but they foresaw that customer expectations were changing rapidly due to digital tech.
They chose to disrupt themselves before someone else did. By 2017, ING reported that time-to-market for new features had improved by an order of magnitude, employee engagement was up, and productivity increased. For instance, one team working on the mobile banking app went from 4 releases per year to biweekly releases, delivering new app features continuously. The architecture evolved as well: they embraced APIs and open banking, allowing faster integration with fintech partners and internal reuse of capabilities. An interesting aspect of ING’s case is how they managed risk and compliance in the new model. They moved risk experts into squads as team members rather than gatekeepers, so compliance was built in from the start (reducing the lengthy back-and-forth typical in banks). This is a great example of “reducing friction” by embedding functions into product teams.
Not everything was smooth – they had to train leaders to let go of micromanagement, and some people struggled with the new autonomy – but overall, ING’s story is cited as proof that even a large, regulated enterprise can attain “startup speed” with the right structural and cultural changes.
Lesson: Bold reorganization and empowerment, combined with architectural simplification, can yield dramatic gains in speed even in highly complex industries. It requires strong executive vision and commitment (ING’s CEO was directly involved and championed the cause), as well as clear communication of the “why” to get everyone on board.
Capital One and the Cloud Bet
Capital One, one of the largest banks in the US, decided early on to aggressively pursue a cloud-first strategy and to in-source tech talent – essentially functioning as a tech company in banking. They shut down their physical data centers entirely in favor of AWS, which gave their developers vastly more agility (provisioning a server went from a 2-3 month process to a couple of minutes).
They also invested in their own cloud management tools and data platforms to make cloud usage self-service but governed. One tangible outcome was the ability to experiment much more freely. Capital One engineers could spin up ephemeral environments to test new ideas or run hackathons to crowdsource innovations, without huge upfront cost or red tape. This fostered a culture of experimentation and learning, central to economies of speed.
As noted earlier, Capital One’s leadership explicitly prioritized capabilities over cost – they assumed if they got faster at delivering customer value, efficiency would follow (which it did). For example, by automating and standardizing their software delivery pipeline, they not only got apps to market faster, they also reduced errors and downtime, which saved costs on the back end. Capital One’s tech transformation is often credited with helping it outpace competitors in offering digital banking features (like real-time fraud alerts, AI-powered assistants, etc.). It also illustrates the importance of talent: they hired hundreds of software engineers and even acquired tech companies (a design firm, a UX company) to infuse modern skills. They knew that to move at tech speed, they needed tech DNA.
Many IT departments stuck in the cost-center mindset try to outsource or avoid hiring expensive talent – Capital One did the opposite, valuing top engineering talent as key to competitive advantage. The result is a Fortune 100 bank that today is mentioned in the same breath as fintech innovators.
Epic Failures
On the other side of the coin, there are cautionary tales of companies that failed to adapt to a speed-first world:
- Kodak
A classic example (outside of pure IT, but instructive nonetheless). They invented the digital camera but were slow to commercialize it for fear of cannibalizing their film business. In a stable world, protecting the profitable status quo seemed rational (economy of scale thinking – maximize the existing product). But the world changed quickly, and Kodak’s hesitation meant it completely lost the market when digital photography surged faster than expected. Kodak’s downfall “underscores the dangers of complacency and the importance of embracing innovation even at the expense of existing revenue streams.” In other words, the cost of slow adaptation was catastrophic. The lesson for enterprises: prioritize speed of learning over short-term efficiency. If you don’t disrupt yourself, someone else will. - Blockbuster
Similarly failed to respond to the shift from physical rentals to online streaming quickly enough. They had massive scale – thousands of stores – but Netflix, a nimble upstart, focused on delivering convenience and continuous innovation in distribution (first DVDs by mail, then streaming, then original content). Blockbuster’s scale became irrelevant as the ground shifted; what mattered was speed to meet new customer preferences. Blockbuster’s leadership famously dismissed streaming, whereas Netflix embraced it and iterated rapidly on the model. The broader moral is that clinging to economies of scale without investing in speed and agility can lead to irrelevance when technology advances. - Nokia
Once the dominant mobile phone maker (with huge scale advantages in manufacturing), Nokia was slow to pivot to the new paradigm of smartphones and app ecosystems. Internal bureaucracy and fear of risk played a role – by the time they tried to catch up (with Windows Phone), Apple and Android, which iterated quickly and encouraged a wide developer ecosystem, had locked up the market. Nokia’s story highlights that even having great talent and past innovation (they had touchscreen prototypes and app store ideas) isn’t enough if your organization can’t execute quickly and decisively on disruptive changes.
In all these failures, a common theme emerges: lack of agility and cultural inertia. These companies optimized for doing what they already did well at greater scale or efficiency, and underestimated the need for rapid strategic pivots. They were overtaken by more agile competitors or shifting landscapes. For today’s enterprise architects, these stories are sobering reminders: the cost of not moving fast is often far greater than the cost of occasional inefficiency or failed experiments. It reinforces the need to bake adaptability into the enterprise’s structures, systems, and strategy.
Conclusion: Architecting for Continuous Adaptation
The evolution from economies of scale to economies of speed represents a fundamental shift in enterprise strategy – one that enterprise architects are central to enabling. IT is no longer just about running large systems cheaply; it’s about building the organizational muscle to respond to change rapidly and continuously deliver innovation. This requires rethinking architecture not as a static master plan, but as a living, evolving framework of principles, platforms, and team structures that together maximize flow and minimize time-to-value.
We explored how platform thinking can provide the foundation for both speed and scale – creating standardized building blocks (APIs, infrastructure, tools) that teams can leverage to accelerate their work without reinventing the wheel. We saw that organizing into product-aligned teams (as per Team Topologies and agile models) breaks the silos and gives teams end-to-end control, drastically reducing coordination overhead. And we highlighted the importance of a product-centric operating model, where funding and accountability align with long-lived product teams, ensuring continuous improvement and alignment to business outcomes.
For enterprise architects, these approaches translate into actionable playbooks: invest in internal developer platforms and “golden path” tooling, champion org changes that bring IT people closer to the business (even if it means redefining roles and retraining staff), and establish lean governance via automation and coaching rather than heavy manuals. Architects should also promote a culture of experimentation – for example, encouraging A/B testing, pilot programs, hack days – to keep the organization learning. Modern architectural principles like event-driven microservices, domain-oriented architectures, and zero-trust security all support greater flexibility and should be in the architect’s toolkit, but the technology must go hand in hand with cultural change.
It’s important to note that speed is not achieved by chaos or reckless hacking; it arises from deliberate design of systems and organizations. As one transformation expert quipped, “slow chaos is not order” – meaning if you go fast without discipline, you get chaos, but going slow doesn’t guarantee order either. The goal is fast flow with control. Successful companies achieve this by automating controls, building quality in, and empowering people to make good decisions locally. Enterprise architects play a key role in designing these socio-technical systems – part engineer, part strategist, and part coach.
Finally, the ultimate measure of success in adopting economies of speed is business impact. Faster time-to-market, higher customer satisfaction (because you’re delivering features they want when they want them), and the ability to pivot when conditions change are competitive advantages that will define the winners in almost every industry. IT and architecture are at the forefront of this fight.