

Once the LLM generates an answer based on retrieved documents, there are a few additional steps that can enhance the quality and reliability of the RAG system:
Answer Post-Processing
- Source citing
In many enterprise use-cases, it’s valuable to include references to where the information came from (to build user trust and allow them to dig deeper). We can map any content in the answer back to the source documents. A simple method is to have the LLM include an identifier when using a chunk (some applications do like “[1]” which corresponds to document 1, etc.). If not, we can post-process by checking which documents had the keywords present in the answer. This can get tricky, so a pragmatic approach: if each retrieved chunk had a title or ID, you can append something like “(Source: Document A)” to the answer if you know Document A was used. Some RAG implementations explicitly prompt the model: “Include the source name for each fact you use.” - Answer filtering
Ensure the answer meets guidelines – e.g., no disallowed content. If the model might produce something offensive or leak sensitive info, you should run it through a content filter. NVIDIA’s NeMo has tools for this (and Databricks has “Lakehouse Monitoring” that can flag toxic or hallucinated outputs). If the answer violates any policy (like it contains private data it shouldn’t), you may either remove that part or refuse the answer with a safe fallback. - Formatting and clarity
You might want to format the answer nicely (markdown bullet points, etc., if delivering via an interface). This is more of an application layer concern, but it helps to make the output user-friendly. One can also correct minor grammar issues via a proofreading model or function if needed.
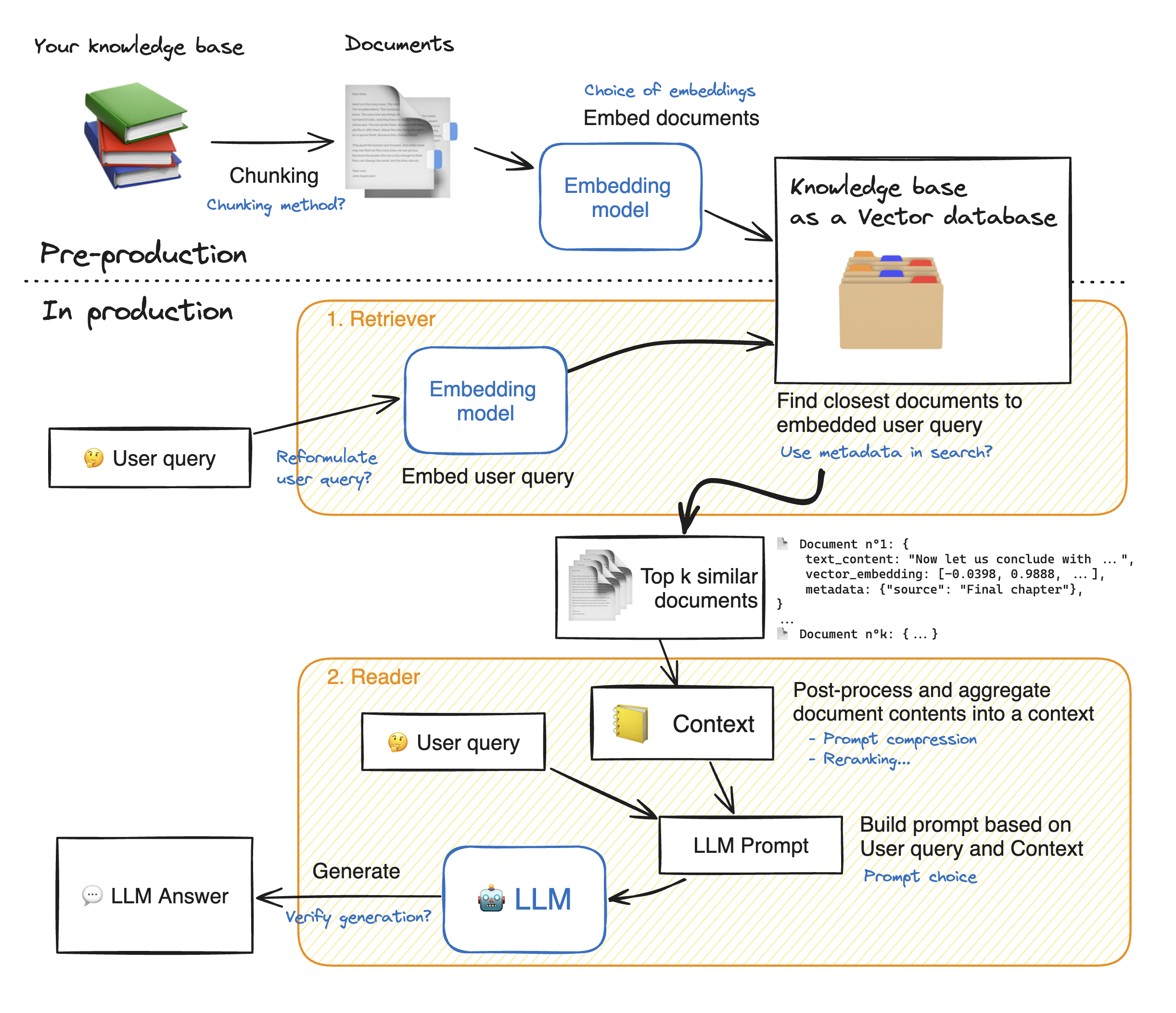
Evaluation (Offline)
Building a RAG system is not a one-and-done task; you need to evaluate its performance and iterate. Key evaluation dimensions include:
- Accuracy/Quality: Does the LLM’s answer correctly address the query using the documents? Does it contain factual errors or unsupported statements?
- Coverage: Is the retrieved document set appropriate? Did the retriever miss something important (false negatives) or include irrelevant stuff (false positives)?
- Efficiency: What’s the latency from query to answer? Can it handle the expected load (QPS)? What’s the throughput of embedding models and LLM?
- Safety: Does the system avoid prohibited content? Does it detect when it should say “I don’t know” versus giving a wrong guess?
For systematic evaluation, you can create a test set of query-> expected answer pairs (if available). If not, you might rely on user feedback or generate some synthetic Q&A pairs from docs to test it.
NVIDIA’s NeMo Evaluator is a tool aimed at simplifying LLM evaluation by providing automated benchmarking against a variety of metrics and even using LLMs to judge outputs. For example, NeMo Evaluator can run your model on a suite of standard tasks or custom Q&A pairs and compute scores, even employing an “LLM-as-a-judge” approach where a strong model (like GPT-4 or a reward model) scores the answers. This helps catch regressions, especially if you fine-tune the model or update the knowledge base. It’s important to evaluate not just on the new task but also ensure the model hasn’t forgotten how to do general language tasks (no catastrophic forgetting).
Meanwhile, Databricks/MLflow provides integrated tools for evaluating and monitoring LLM applications. For instance, MLflow 2.x introduced an mlflow.evaluate() API for LLMs, and notebooks exist (e.g., “RAG Evaluation with MLflow” examples) that show how to compare different RAG configurations using an LLM judge model (like Llama-2-70b as a judge). A typical workflow could be:
- Log your RAG system’s components or parameters (embedding model, vector index type, LLM version) as an MLflow Run.
- For a set of test queries, have the system produce answers, then use
mlflow.evaluatewith an evaluator (could be a QA evaluator or a custom metric) to score the answers versus references or have an LLM rank them. MLflow can record metrics like accuracy, BLEU (for known answers), or even cost and latency per query. - Use the MLflow Tracking UI to compare runs. For example, you might compare “RAG with embedding model A + re-ranker vs. RAG with embedding model B” to see which gave better accuracy on your test questions. One can also track the average inference time and see the impact of optimizations.
Continuous Monitoring
In production, you should monitor both system performance and output quality. This includes:
- Latency logs (how long each stage takes – embedding, retrieval, LLM generation – so you can spot bottlenecks).
- Usage of each document (are there documents never retrieved? Maybe they are irrelevant or maybe embedding failed – could prune them or investigate).
- User feedback or ratings if available (perhaps through thumbs-up/down in a chat UI).
- Automated safety scans on outputs (flag if the LLM output likely contains something it shouldn’t, so you can review and adjust prompts or filters).
Databricks suggests a Lakehouse Monitoring solution that can “automatically scan application outputs for toxic, hallucinated, or otherwise unsafe content” and feed dashboards or alerts. This can be implemented by logging each answer and using either simple keyword checks or an AI-based detector to classify them. For hallucination detection, one approach is to verify facts in the answer against the source docs (not trivial – sometimes done by another retrieval+check, or using an LLM to highlight which sentence might be made-up).
Evaluation is both an offline exercise to benchmark the system and an ongoing process in production to ensure it continues performing well as data or usage patterns change. By combining tools like NeMo Evaluator for rigorous benchmarking with MLflow tracking for experiment management, and deploying monitoring for live traffic, you can close the loop and continually improve your RAG system.
