

Retrieval-Augmented Generation (RAG) is an architectural approach that improves the accuracy and reliability of LLM applications by grounding their outputs on external data. In a RAG system, when a user asks a question, the system retrieves relevant documents from a knowledge base and provides them as context for the LLM to generate a factual, up-to-date answer.
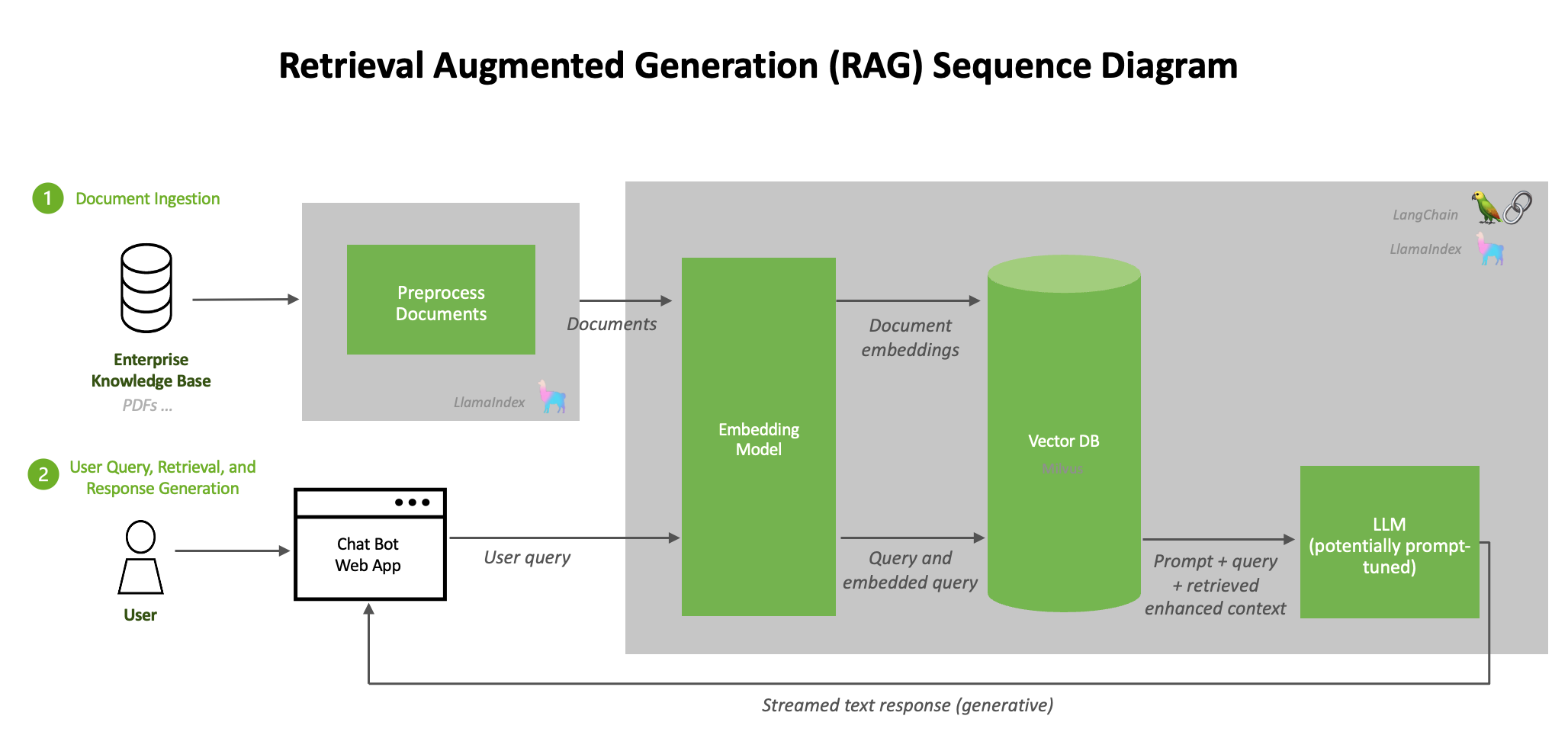
This technique helps enterprises maintain up-to-date, domain-specific knowledge in LLM responses while reducing hallucinations. In this comprehensive multi-part guide, we will walk through how to build an end-to-end production-grade RAG pipeline using NVIDIA’s AI tools and the Databricks Lakehouse platform on AWS, following best practices as of 2025.
We cover every stage of the pipeline, including data ingestion and curation, text preprocessing and chunking, embedding generation, vector storage and retrieval, query workflow and ranking, LLM integration for answer generation, post-processing and evaluation, performance optimizations, and deployment options. Throughout, we highlight strategies to minimize latency, maximize answer accuracy, and simplify operations for enterprise settings. By the end of this series, you will have a clear blueprint for implementing RAG in production – leveraging NVIDIA NeMo for data processing, model customization, and optimization, alongside Databricks Lakehouse capabilities for data management, vector search, and MLOps.
Below are the links to all dive-ins:
- Data Ingestion →
Ingested and curated data using NeMo Data Curator and Delta Lake, ensuring a high-quality knowledge source - Preprocessing & Chunking →
Preprocessed and chunked documents to the right granularity for retrieval. - Embedding Generation →
Generated embeddings for each chunk (using models like E5 or custom ones) and stored them in a vector index. - Vector Storage →
Set up vector search (with Databricks’ integrated solution for ease and governance), enabling fast similarity queries. - Query Handling →
Handled query processing by embedding user questions and retrieving relevant context passages. - LLM Integration & Generation→
Integrated a Large Language Model (which could be custom fine-tuned via NeMo for domain alignment) to generate answers using the retrieved context. - Post Processing & Evaluation →
Evaluated outputs and set up monitoring (via NeMo Evaluator, MLflow, etc.) to ensure quality and track performance. - Performance Optimization →
Optimized the system for production using NVIDIA TensorRT-LLM, quantization, and other techniques to achieve low latency and cost-efficient inference. - Deployment & Operations →
Deployed the solution on AWS with considerations for scalability, reliability, and security (leveraging Triton or Databricks Model Serving, and autoscaling where possible).
