

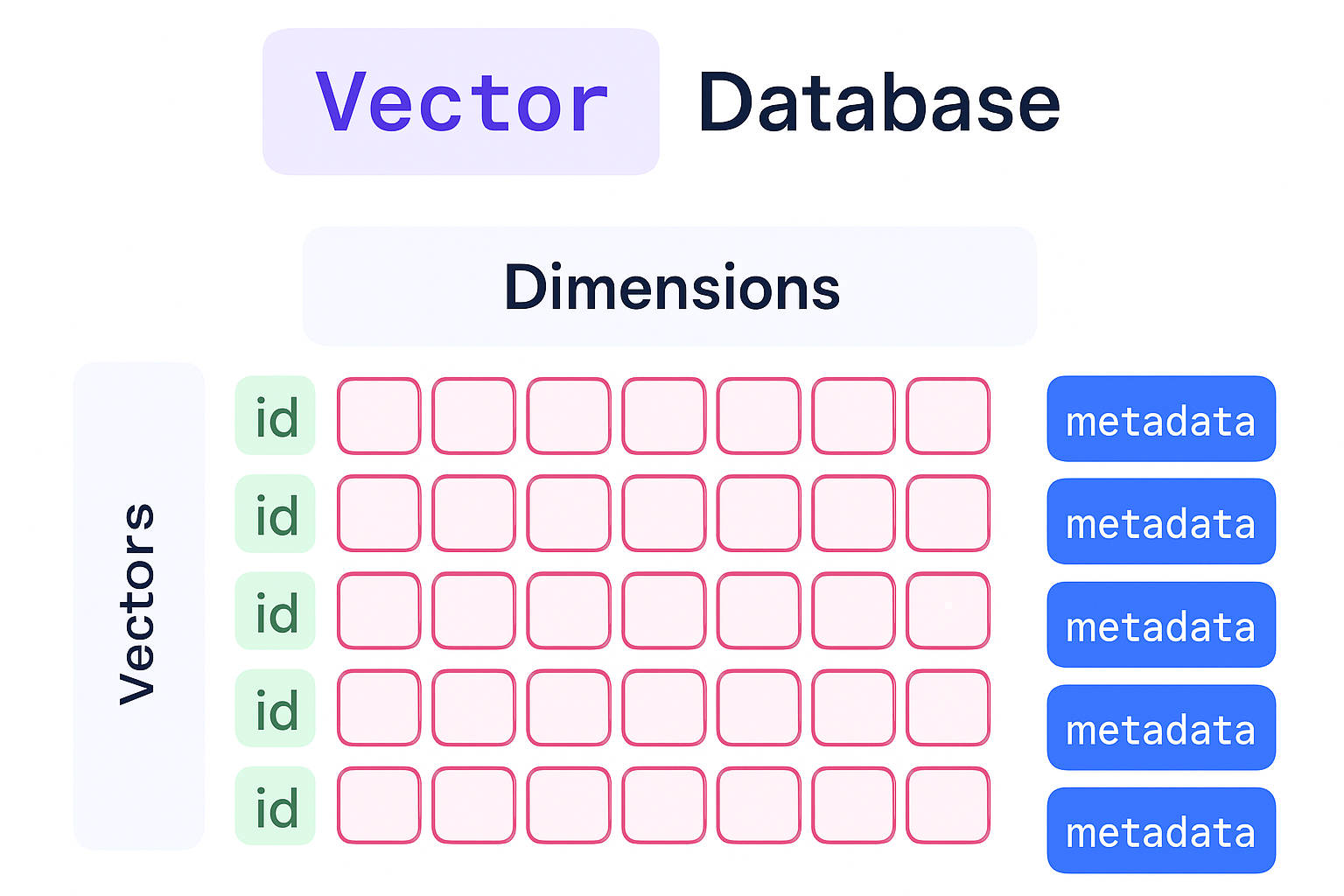
A core component of RAG is the vector store – essentially, a database or index that holds all document embeddings and can quickly retrieve the most similar ones to a given query embedding. The choice of vector storage can significantly impact the system’s latency, scalability, and ease of integration. We will explore two routes: using Databricks’ built-in Vector Search vs. custom solutions like FAISS, Weaviate or Pinecone.
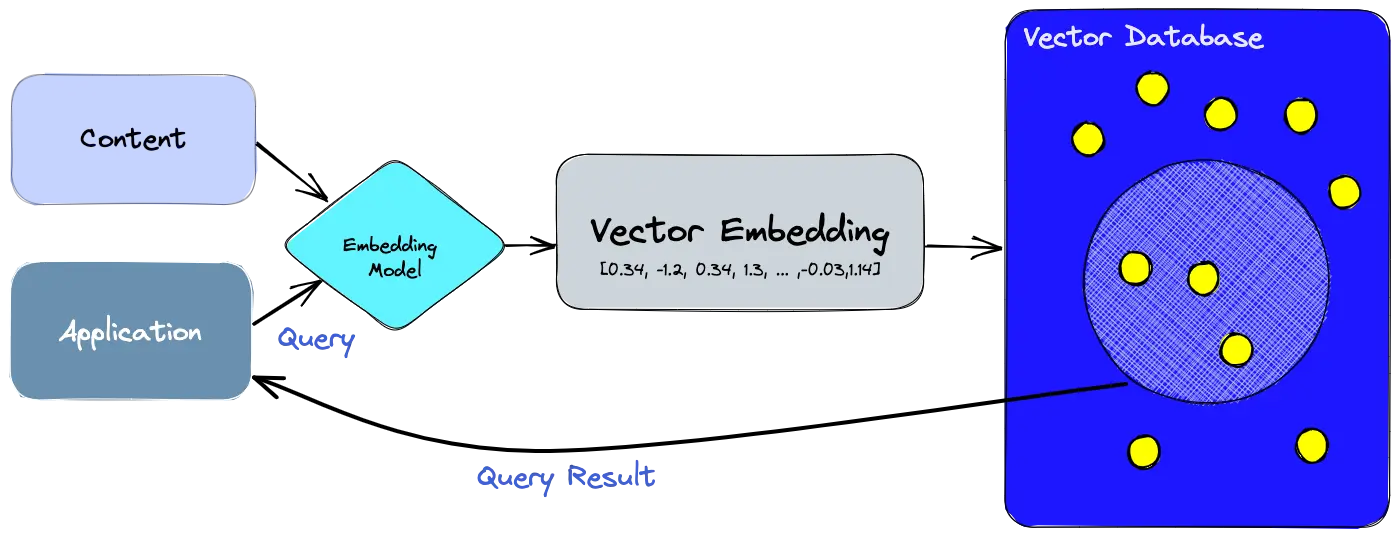
Option 1: Databricks Vector Search (Lakehouse native)
Databricks has introduced a fully managed vector search capability integrated into its Lakehouse Platform. It’s designed to be “fast with low TCO” (reportedly up to 5× lower latency than some other providers) and offers one-click synchronization from a Delta table to a vector index. Key advantages include:
- Simplicity: You can select a Delta table (with text or with precomputed embeddings) and an embedding model (via a serving endpoint) and create an index with a single API call or UI click. No need to manage separate ETL for the vector DB – it will automatically embed new data and update the index.
- Automatic syncing: As new data is added or updated in the source Delta table, Databricks handles updating the index (using Delta Sync APIs). Under the hood, it manages failures, retries, and batches to efficiently use the embedding endpoint and keep the index fresh.
- Enterprise governance: The vector search integrates with Unity Catalog for permission control. This means you can enforce that only certain users or roles can query certain subsets of the vector data, just like you would with tables. It also means you don’t have to duplicate your security model for a separate vector DB – a big plus for simplifying ops and compliance.
- Serverless scalability: Databricks’ vector search runs on a serverless infrastructure that scales with the workload. You don’t manually provision index servers – the platform takes care of scaling out for large indexes or heavy query volumes, which lowers the ops burden.
To use Databricks Vector Search, one would typically do the following (in code or UI):
- Create a Vector Index – e.g., via REST API or Python SDK, specify the name of the index and which embedding model to use. This sets up an endpoint.
- Sync with Delta Table – point the index at your Delta table of documents/chunks and the column to embed (or if you have stored embeddings, it can use those). If providing a model endpoint, it will embed all records and build the index. This corresponds to Step 1 and 2 described in the Databricks blog.
- Query the index – using either SQL functions (Databricks has a
VECTOR_SEARCHSQL function if you want to query in SQL) or API calls, retrieve top-k similar vectors for a given query vector.
This integrated route is very attractive for those already using Databricks, as it cuts down on infrastructure to manage.
Option 2: External or Custom Vector Database – In some scenarios, you might opt for a standalone vector store. Popular choices include FAISS (Facebook AI Similarity Search library), which is an open-source C++/Python library, or cloud-managed solutions like Weaviate, Pinecone, Milvus, etc. Here’s how they compare:
- FAISS (library): FAISS allows you to build an in-memory index of vectors and supports various algorithms (flat index, IVF, HNSW, etc.). It’s great for prototyping or for moderately sized datasets that can fit in RAM. You could integrate FAISS in a Python service or even within a Spark UDF (though typically you’d use it in a separate service). FAISS gives a lot of control – you can choose cosine vs L2 similarity, use GPU acceleration for indexing/search, and fine-tune parameters like the number of clusters or graph efSearch (if using HNSW). The downside is you have to manage persistence and scaling yourself (though you can save indexes to disk).
- Weaviate (vector DB): Weaviate is an open-source vector database that can run as a service (or you can use their cloud service). It provides RESTful APIs to upsert vectors, does automatic indexing (HNSW under the hood by default), and supports hybrid queries (combining keyword filters with vector search). For example, you can store each chunk as an object with fields (text, title, etc.) and a vector; then query with a vector plus a keyword filter like
category="finance". It also offers modules for things like text2vec (if you want it to generate embeddings internally). Running Weaviate means deploying an extra component (for AWS, possibly on EC2 or EKS), but it’s horizontally scalable and optimized for large volumes. - Others: Pinecone is a managed service (proprietary) where you just use an API and don’t worry about infrastructure – similar to what Databricks provides, but cloud-agnostic and not directly tied to Delta Lake. Milvus is another open source similar to Weaviate. There’s also Elasticsearch’s vector capabilities if you already use ELK stack, or even using Annoy or ScaNN for specific cases.
For this guide, let’s assume we choose the Databricks Vector Search for its ease, but we’ll illustrate usage of FAISS in code to show the fundamentals of vector retrieval:
import numpy as np
import faiss
# Suppose we have embeddings array of shape (N, d)
embeddings = np.array(embeddings).astype('float32') # from previous part
index = faiss.IndexFlatIP(embeddings.shape[1]) # inner-product (cosine if normalized)
index.add(embeddings) # add all document vectors to the index
# Later, for a new query:
query_vec = model.encode(["<user query text>"], normalize_embeddings=True)
query_vec = np.array(query_vec).astype('float32')
D, I = index.search(query_vec, k=5) # retrieve top-5 most similar
print("Top 5 document indices:", I[0])
In this snippet, we create a FAISS flat index that uses Inner Product similarity. We assume we normalized all vectors, so maximizing inner product is equivalent to cosine similarity. We add all our document vectors, and then we can search the index with a query vector to get the top 5 similar documents. In practice, one would store the I (indices) and map them back to the actual document texts or IDs (remember we have metadata mapping each vector to a chunk).
For larger scale, one would use a FAISS index with partitioning or HNSW (Hierarchical Navigable Small World graph) which can handle millions of vectors more efficiently than a flat index (with a minor accuracy trade-off). Databricks’ vector search likely uses HNSW under the hood as well (they mention HNSW as best-in-class performance for similarity search). The key point is that approximate nearest neighbor methods dramatically speed up search at scale.
Considerations for vector storage
- Persistence: If using an external library like FAISS, remember to save the index to disk and load it on service startup, so you don’t have to re-embed everything each time. Databricks Vector Search handles persistence for you (the index is managed in their platform, likely persisted to disk behind the scenes).
- Filtering and metadata: Often you want to not just retrieve by similarity, but also apply filters (e.g., only retrieve documents from a certain date range or category). Some vector DBs support filtering natively. If using FAISS alone, you might need to filter results post hoc by checking metadata of the top-k and maybe retrieving more than k to filter down. In Databricks, since the index is tied to a Delta table, you could query with an SQL where clause + vector search UDF to combine filtering by fields with similarity.
- Security: Ensure that the vector store doesn’t inadvertently leak data. If you use a managed service, consider encryption (some offer encrypting vectors at rest). With Databricks, Unity Catalog governance covers who can query the index, which is a nice security layer.
- Refreshing: When underlying data updates, plan how to update the vectors. With Databricks, the sync API automates re-embedding on new/changed records. With an external store, you may need a process to watch for new data (perhaps using Delta change data feed or timestamps) and update the index (insert new vectors, delete or reindex changed ones). Keeping the knowledge base fresh is important for many RAG use cases (so that yesterday’s info is available today).
At this point, we should have a functional vector index of all document chunks. Now we can handle incoming queries by searching this index. That’s the focus of the next part.
